
Web scraping hacks that changed my life
it feels like i'm cheating at this point

When I first started to learn to code I decided it was going to be with web scraping. I saw people that claimed they were making money collecting data on the internet and I thought I could get good enough to make money on Upwork and Fiver.
Turns out I wasn’t willing to work for 5 dollars so that never went anywhere but, my coding journey has completely exploded because of that experience and the skills I learned.
Web scraping is a basic skill that is often overlooked in the world of software engineering, data science, machine learning, and other fields. It is a skill that is easy to learn but can become difficult to master. Even top-level data scientists struggle with creating effective web scraping pipelines.
The truth is, most people don’t have access to large enterprise internal databases, thus data must be collected from the internet. Even OpenAI trains their GPT models on data that they scrape from Quora, Reddit, and other publicly available datasets.
Those who understand its true value unlock a gold mine of data available on the public web.
Data will become the modern-day gold as AI advances, so being able to understand how to collect, process, store, and analyze this data opens up a ton of opportunities.
I’ll reveal a couple of tips and tricks that you can use in your web scraping to take you from a beginner to a master.
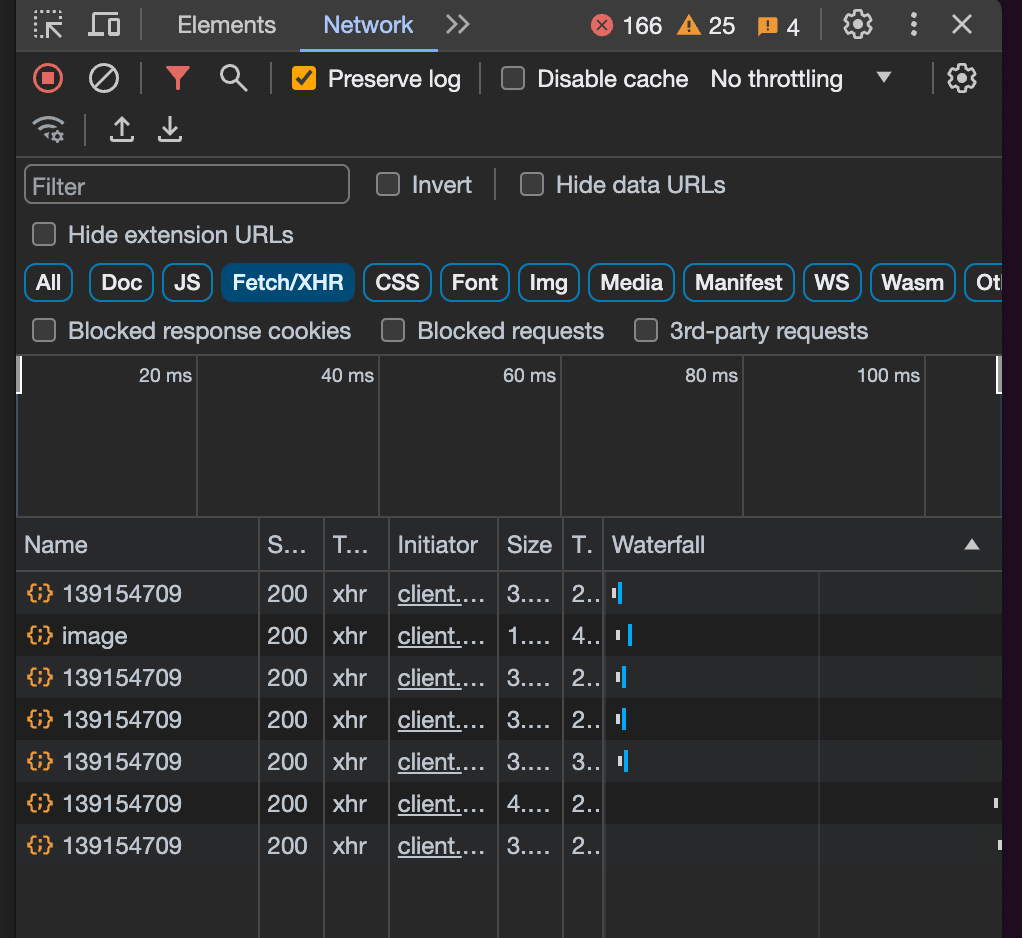
1. The network tab
Every time you load a web page, there are 10s sometimes 100s of scripts and APIs that are running in the background fetching data from databases, doing calculations, and much more.
The great thing is that we can run a lot of these independently in our own code.
To access these you’ll want to
right-click anywhere on a page
click on inspect. This opens Google’s developer tools.

once that opens click on the double arrows at the top if you need to and click on the network tab
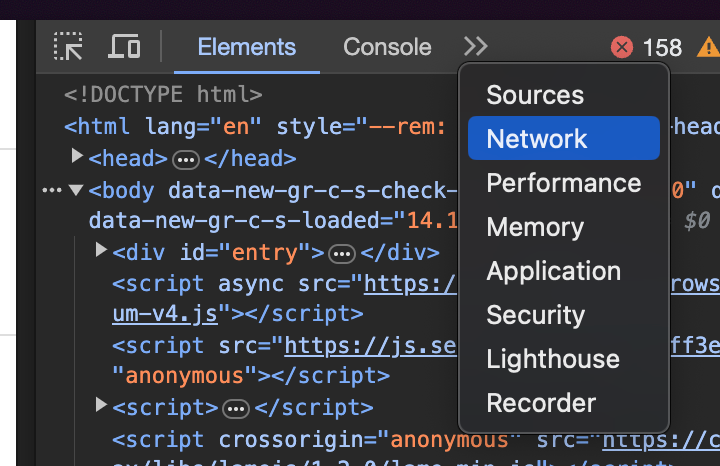
Now change it from “all” to “Fetch/XHR”'. I also like to click “Preserve log” at the top.
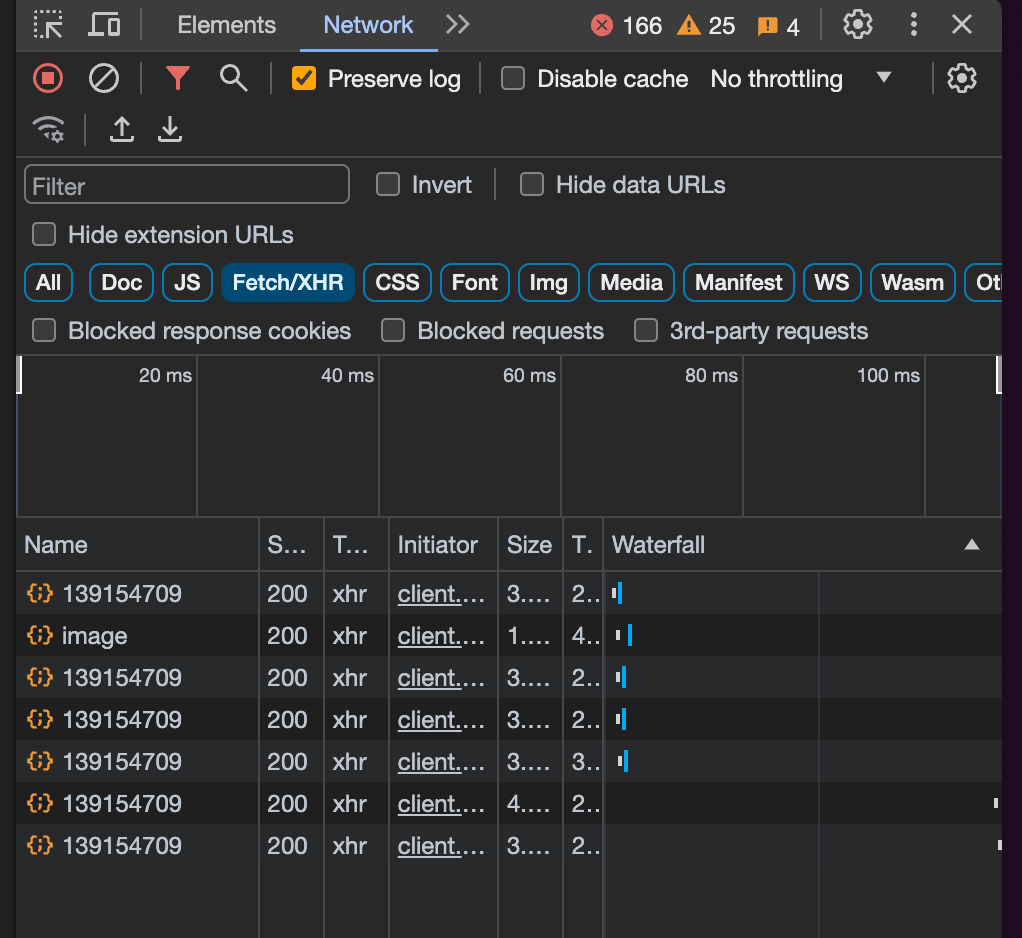
These are all of the APIs and scripts that are being run to fetch data! We can start clicking through these and we can look at the headers, payloads, and the output.
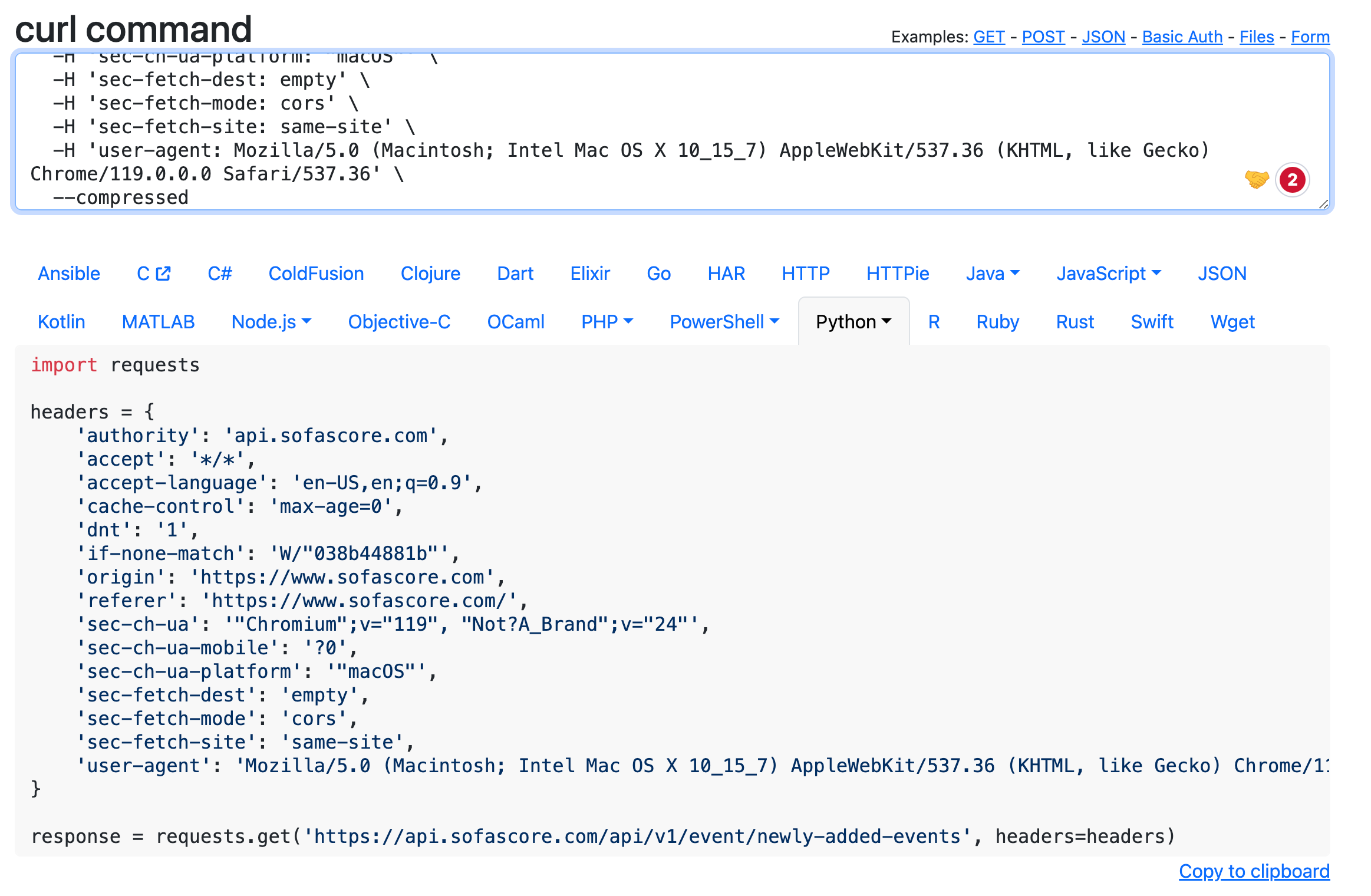
Let’s turn it into Python code. Right-click on the API you want to run, go down to Copy and then click Copy as cURL

Now head over to https://curlconverter.com/ and paste in what you just copied and boom! it gives you all of the Python code you need.

Feel free to play with anything it returns such as the headers, cookies, payload, etc so that you can create a dynamic web scraper.

I use this method a ton. A lot of times it helps with finding and extracting data that I specifically need. If you want to watch a video where I utilize this you can watch this video where I teach how to scrape sofascore.com
2. CSS selectors
If you can learn HTML and CSS you’ll never worry about web scraping again
That sounded inspirational so I put it in a quote block haha.
But there is truth in that. One of the biggest advantages you can get when web scraping is to properly learn how HTML and CSS work so you can utilize CSS selectors.
If you don’t know what CSS selectors are, they are part of the CSS code which allows us to select different HTML and CSS objects in the code.
Using them is made super easy by the BeautifulSoup package in Python.
For example, say we want to get all of the images on a page. CSS and BeautifulSoup make this straightforward.
import requests
response = requests.get('secret-url.com')
from bs4 import BeautifulSoup
soup = BeautifulSoup(response.text, 'html.parser')
images = soup.select('img')The above code makes it simple to grab all of the images.
But let’s say we only want one image. Or a couple that fit a certain attribute instead of every single one on the page.

Let’s take a look at pokemon.com for example.
If you look on the right, we’ve opened the Google developer tools and we can see all of the HTML and CSS compiled to create the page.
If we just wanted the current image, we could use the attributes from the highlighted “img” tag in the console.
image = soup.select_one('img[alt="Hohma and Quaxly Infiltrate Team Star in Pokémon: Paldean Winds"]We could also use nested CSS selectors to drill down into an element.
image = soup.select('div[class="tile-image-wrapper"] img]The above code allows us to essentially path our way down the HTML and CSS as far as we need.
This is just one example, but CSS selectors can start to become much more advanced and you can do incredible things with them. The power of CSS selectors in web scraping can help you create efficient and clean web scraping code.
3. Proxies
Proxies are a thing you hear about a lot but can be confusing at the same time.
I like to think of it as going to Disneyland.
When you go to Disneyland you have a ticket with your image attached to it. Disneyland might end up “blocking” you from entering the park if you’ve had one too many churros at Cars Land.
So what you can do, is dress up like your friend and use their ticket to get into the park.
This is how proxies work. Every computer, router, etc. all have IP addresses that websites can use to track who is accessing their website.
They can do things like an IP ban which means that you can’t access that website anymore if your IP has been blocked. Usually, this happens when you are trying to access the data too fast or access confidential information. Maybe you did it on purpose or maybe you didn’t. Sometimes you will get blocked just for trying to scrape data.
This is where proxies come in. A proxy essentially allows you to borrow someone else’s IP address and access the data through that IP. This makes it so you are able to access the data.
You can get a whole range of proxies from data center proxies which usually have low success rates since they get blocked pretty quickly, to residential proxies which usually have high success rates.
You can either buy specific proxies or use a service that buys them and rotates them for you. I prefer the latter, which can end up costing more but saves you a pretty big hassle of having to buy proxies and worry about when they get blocked or not.
Some of those services are
These services provide an easy-to-use API that allows you to essentially focus on writing code rather than building a big proxy network and having to manage that all the time.
That’s it for this article. These tricks are things that can help you advance your skill set as they have helped me do so.